Waiting for garbage collection can kill parallelism?
I am reposting my mail from Haskell-cafe, since I got no replies in over a week and I think it is an interesting case. I was reading “Parallel Performance Tuning for Haskell” by Jones, Marlow and Singh and wanted to replicate the results for their first case study. The code goes like this:
module Main where
import Control.Parallel
main :: IO ()
main = print . parSumFibEuler 38 $ 5300
fib :: Int -> Int
fib 0 = 0
fib 1 = 1
fib n = fib (n - 1) + fib (n - 2)
mkList :: Int -> \[Int\]
mkList n = \[1..n-1\]
relprime :: Int -> Int -> Bool
relprime x y = gcd x y == 1
euler :: Int -> Int
euler n = length (filter (relprime n) (mkList n))
sumEuler :: Int -> Int
sumEuler = sum . (map euler) . mkList
sumFibEuler :: Int -> Int -> Int
sumFibEuler a b = fib a + sumEuler b
parSumFibEuler :: Int -> Int -> Int
parSumFibEuler a b = f \`par\` (e \`pseq\` (e + f))
where f = fib a
e = sumEuler bIn the paper authors show that this code performs computation of fib ans
sumEuler in parallel and that good speed-up is achieved:
To make the parallelism more robust, we need to be explicit about the evaluation order we intend. The way to do this is to use
pseqin combination withpar, the idea being to ensure that the main thread works onsumEulerwhile the sparked thread works onfib. (…) This version does not make any assumptions about the evaluation order of+, but relies only on the evaluation order ofpseq, which is guaranteed to be stable.
These results were obtained on older GHC version ((Paper does not mention which version exactly. I believe it was 6.10, since “Runtime Support for Multicore Haskell” by the same authors released at the same time uses GHC 6.10)). However, compiling program with:
$ ghc -O2 -Wall -threaded -rtsopts -fforce-recomp -eventlog parallel.hsand then running on GHC 7.4.1 using:
$ ./parallel +RTS -qa -g1 -s -ls -N2yields a completely different result. These are statistics for a parallel run on two cores:
SPARKS: 1 (1 converted, 0 overflowed, 0 dud, 0 GC'd, 0 fizzled)
INIT time 0.00s ( 0.00s elapsed)
MUT time 2.52s ( 2.51s elapsed)
GC time 0.03s ( 0.05s elapsed)
EXIT time 0.00s ( 0.00s elapsed)
Total time 2.55s ( 2.56s elapsed)
Running the same code on one core results in:
SPARKS: 1 (0 converted, 0 overflowed, 0 dud, 1 GC'd, 0 fizzled)
INIT time 0.00s ( 0.00s elapsed)
MUT time 2.51s ( 2.53s elapsed)
GC time 0.03s ( 0.05s elapsed)
EXIT time 0.00s ( 0.00s elapsed)
Total time 2.55s ( 2.58s elapsed)Looking and MUT (mutator time) it looks that there is no speed-up at all.
Investigating eventlog using ThreadScope sheds some light on execution of a
program:
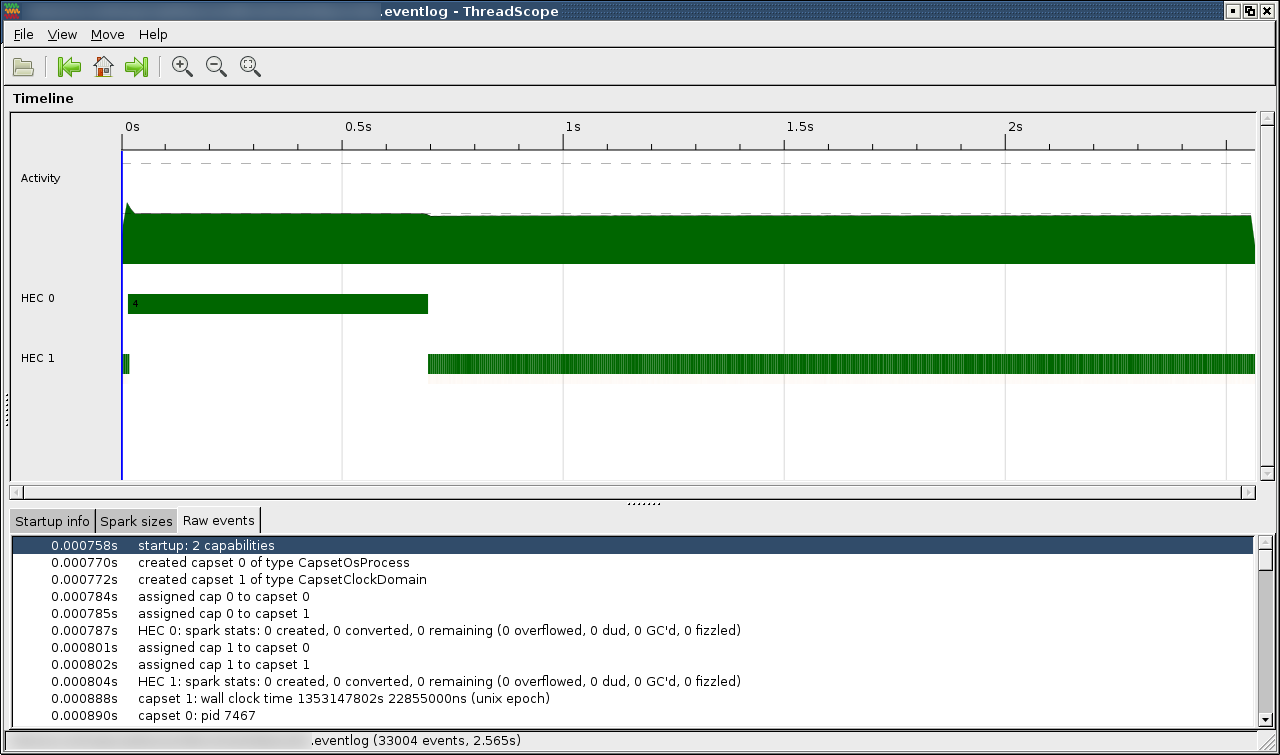
Both threads start computation, but HEC 1 soon blocks and only resumes when HEC 0 finishes computation. Zooming in it looks that HEC 1 stops because it requests garbage collection, but HEC 0 does not respond to that request so GC begins only when HEC 0 is done with its computation:
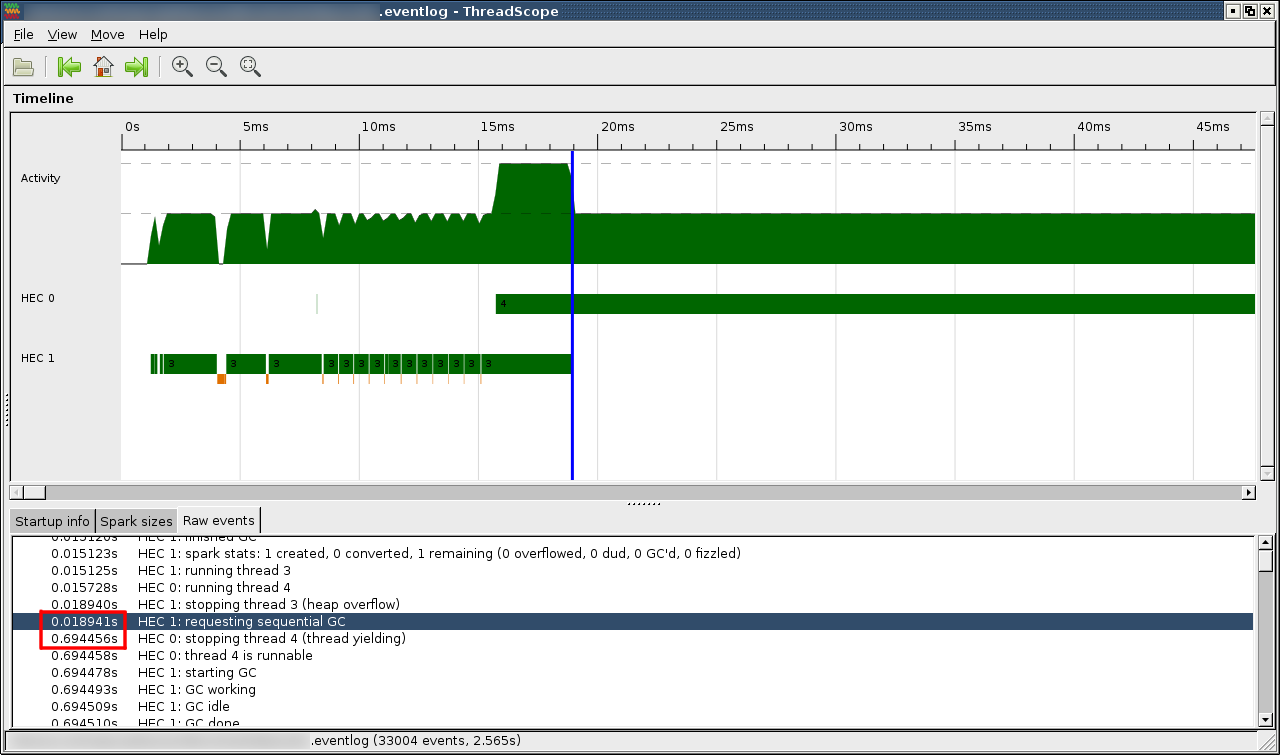
Why does this happen? I am no expert on GHC’s garbage collection, my only knowledge of that comes from section 6 of “Runtime Support for Multicore Haskell”. If I understood correctly this should not happen - it certainly didn’t happen when the paper was published. Do we have a regression or am I misunderstanding something?